Feed-forward 3D reconstruction from inconsistent, distractor-heavy image collections.
Current end-to-end multi-view 3D reconstruction methods achieve impressive results, but they rely on a restrictive static-world assumption: input collections are expected to be distractor-free and geometrically consistent across views. This assumption breaks in real captures, where transient objects, occluders, and inconsistent viewpoints frequently appear.
We propose Visual Geometry Transformer in the Wild (VGTW), a feed-forward framework for robust reconstruction from inconsistent image sets. Our core idea is to explicitly isolate distractor-contaminated regions while preserving the stable scene content shared across views. To do this, we introduce a Distractor-aware Training (DAT) strategy with distractor suppression, cross-view consistency, and an auxiliary mask-prediction head trained from pixel-level distractor annotations.
The resulting model directly predicts clean point maps and depth without extra 3D supervision, and it generalizes well to challenging in-the-wild scenes with heavy occlusions.
VGTW builds on the feed-forward geometry prediction pipeline and introduces a distractor-aware training strategy tailored for inconsistent image collections. Image tokens interact through frame-wise and global attention, while DAT explicitly discourages distractor leakage and preserves consistent geometry.
| Method | Processing | Low Occlusion | Medium Occlusion | High Occlusion | Overall Average | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc ↓ | Comp ↓ | NC ↑ | Acc ↓ | Comp ↓ | NC ↑ | Acc ↓ | Comp ↓ | NC ↑ | Acc ↓ | Comp ↓ | NC ↑ | ||
| DUSt3R | Pair-wise | 0.043 | 0.035 | 0.682 | 0.044 | 0.102 | 0.763 | 0.026 | 0.102 | 0.798 | 0.037 | 0.080 | 0.747 |
| MaSt3R | Pair-wise | 0.044 | 0.120 | 0.636 | 0.064 | 0.136 | 0.691 | 0.028 | 0.216 | 0.751 | 0.045 | 0.157 | 0.692 |
| Fast3R | Multi-image | 0.037 | 0.049 | 0.639 | 0.057 | 0.062 | 0.681 | 0.030 | 0.096 | 0.720 | 0.041 | 0.069 | 0.680 |
| VGGT | Multi-image | 0.040 | 0.057 | 0.663 | 0.051 | 0.120 | 0.632 | 0.032 | 0.262 | 0.625 | 0.041 | 0.146 | 0.640 |
| VGTW(VGGT) | Multi-image | 0.033 | 0.029 | 0.695 | 0.041 | 0.095 | 0.724 | 0.025 | 0.228 | 0.693 | 0.033 | 0.117 | 0.704 |
| π3 | Multi-image | 0.034 | 0.051 | 0.699 | 0.084 | 0.096 | 0.676 | 0.036 | 0.078 | 0.753 | 0.051 | 0.074 | 0.709 |
| VGTW(π3) | Multi-image | 0.028 | 0.033 | 0.625 | 0.035 | 0.073 | 0.715 | 0.019 | 0.076 | 0.734 | 0.027 | 0.060 | 0.692 |
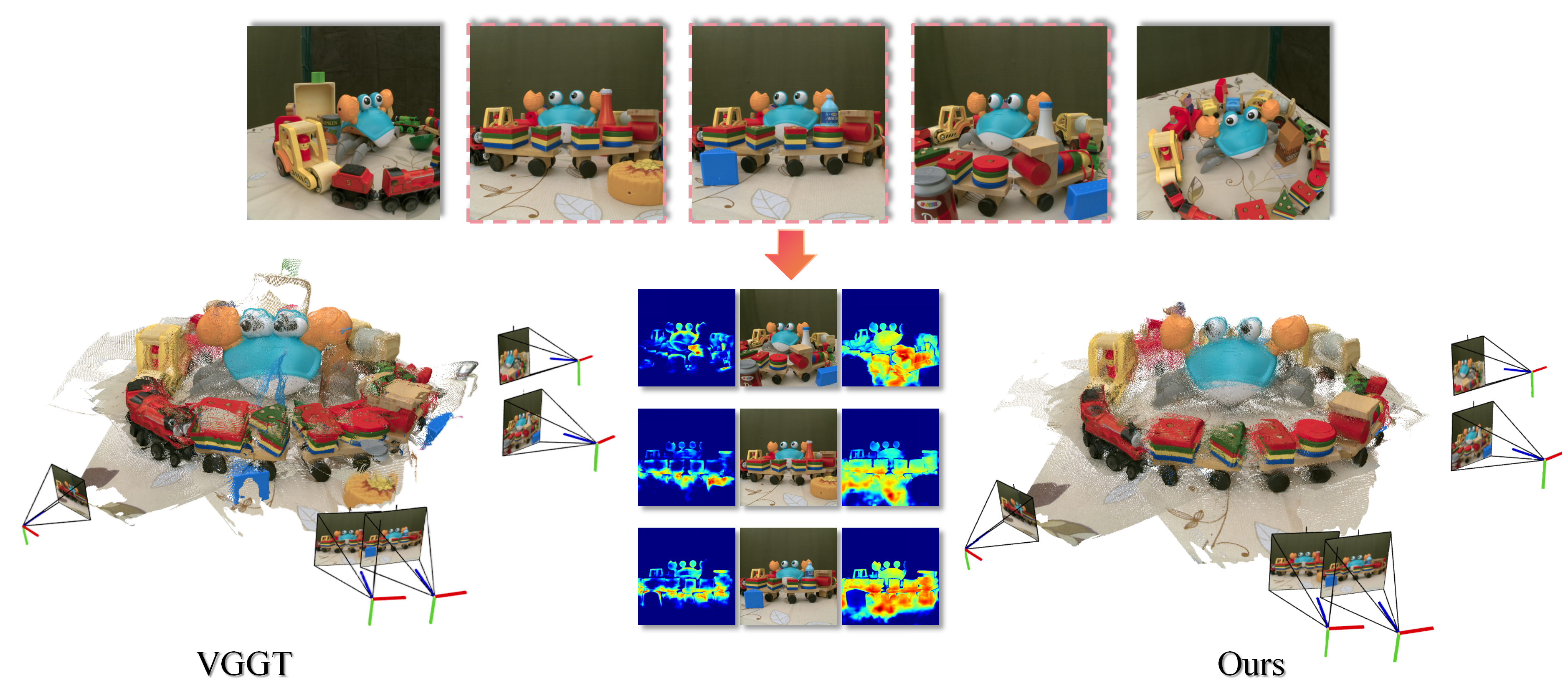
Compare reconstructed geometry from VGTW, VGGT, and Easi3R across representative scenes.
@misc{pan2026vgtw,
title={Visual Geometry Transformer in the Wild: Distractor-Free 3D Reconstruction},
author={Pan, Tianbo and Yang, Xingyi and Wang, Shizun and Wang, Xinchao},
year={2026},
note={Project page manuscript}
}